2026. 1. 9. 15:36ㆍ백엔드

안녕하세요!
이번에 하는 프로젝트에서 음성인식으로 주문하기 기능이 있어 구현해보려고 합니다.
Google Cloud Speech-to-Text란?
Google Cloud Speech-to-Text(STT)는 음성 오디오를 전송하면 텍스트로 반환해주는 Google Cloud의 음성인식 API 서비스입니다. 애플리케이션에서 마이크/오디오 파일을 입력으로 받아 음성 → 텍스트 기능을 빠르게 붙일 때 사용합니다.
링크는 여기를 클릭하시면 됩니다.
1. Google Cloud Speech-to-Text 설정
1-1. API 설정


관리 > 사용자 인증 정보 만들기 선택
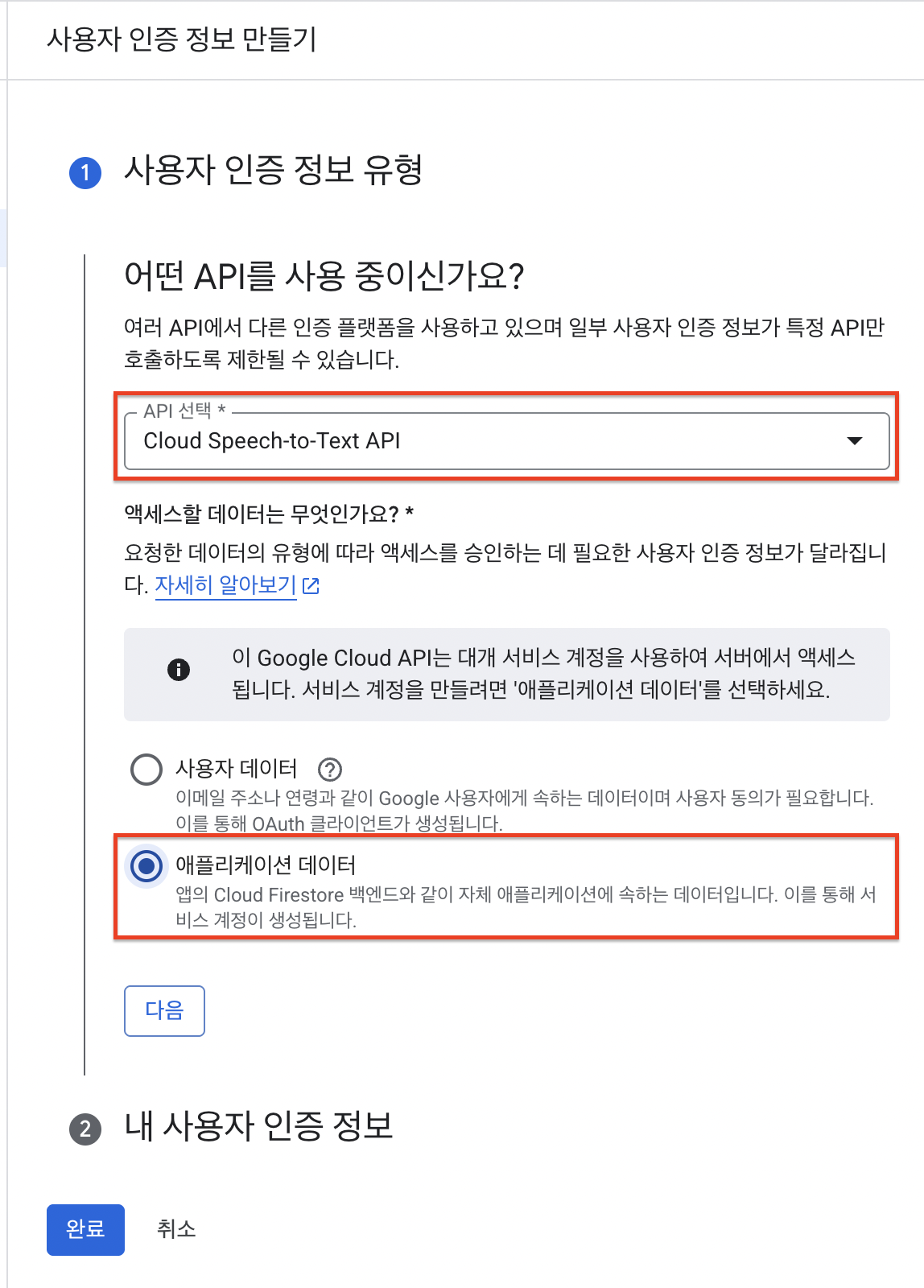
사용자 인증 정보의 API선택과 액세스할 데이터 유형을 선택하고 [다음] 버튼을 누릅니다.

그리고 서비스 계정을 만듭니다.
2번 권한과 3번 액세스 권한이 있는 주 구성원은 선택사항으로 미입력 후 완료했습니다.
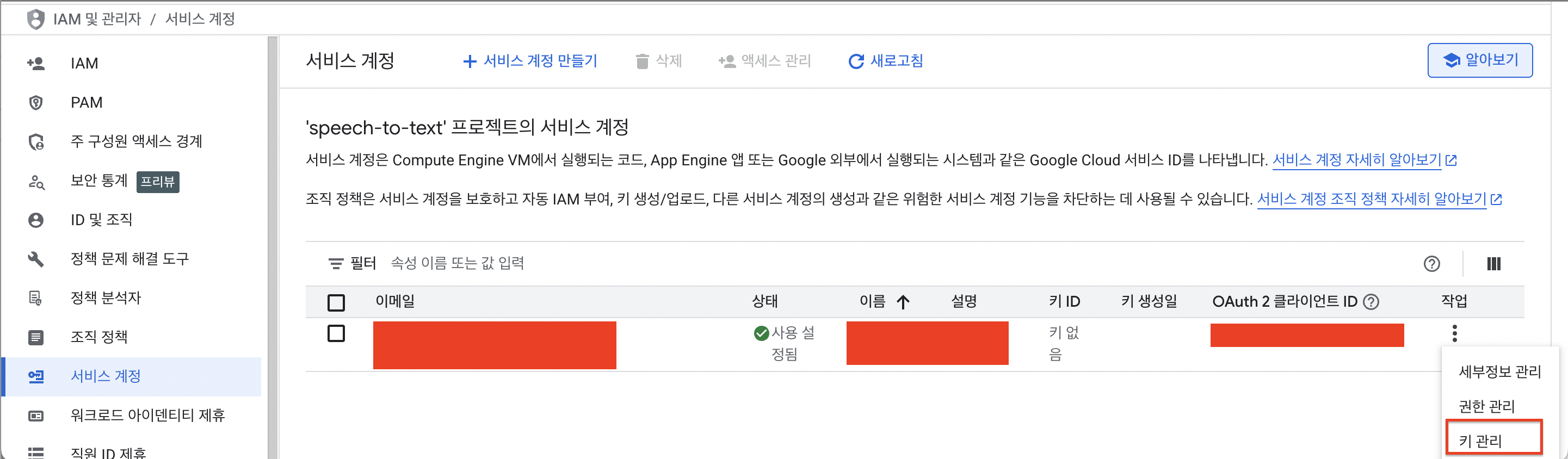

다시 서비스 계정 탭으로 들어와서 만들어진 서비스 계정 > 작업 > 키관리를 선택합니다.
그리고 키추가 선택!

JSON으로 만들기 선택하면 키가 다운로드 받아집니다.
1-2. recognizer 설정

구글 클라우드에 recognizer라고 검색하면 recognizer를 생성할 수 있는 페이지가 나온다.
location과 model은 본인의 쓰임에 맞게 만들면 되는데 나는 짧은 음성인식이 적합하여 short로 해주었다.
2. 인증 설정
인증 설정 방법이 여러개 있습니다.
발급받은 키 json파일을 프로젝트에 넣어두고 yml파일에 해당 키를 환경변수로 설정하는 방법이 있습니다만, 이건 보안이 중요한 키 파일을 그대로 프로젝트에 노출시키게 되어 다른 방법을 찾아보았습니다.
google 문서에 나와있는 ADC 인증방식을 사용하기로 결정. 참고로 이 방법으로 로컬에서만 돌리고 운영배포할때는 다른 방법으로 키를 주입해야할 것 같다. 그 때가서 다시 글을 작성해보겠습니다.
$ brew install --cask google-cloud-sdk // Google Cloud SDK 설치
$ gcloud init
$ gcloud auth application-default login Your browser has been opened to visit:
터미널에 해당 명령어를 순서대로 입력해서 google cloud CLI를 설치해줍니다.

세번째 명령어를 실행하면 브라우저에 google로그인 창이 뜨고 로그인을 완료하면 아래 처럼 완료창이 뜹니다.
You are now logged in as [$내 구글 메일주소].
Your current project is [None]. You can change this setting by running:
$ gcloud config set project PROJECT_ID
하지만 다시 터미널을 보면 이런 알림이 뜹니다.
이건 현재 상태는 계정 로그인만 되었고, gcloud 기본 프로젝트가 아직 지정되지 않은 상태라는 뜻입니다.
위에 구글 홈페이지에서 만든 프로젝트의 ID를 설정해보겠습니다.
$ gcloud projects list -- 프로젝트 리스트 확인
$ gcloud config set project ${내 프로젝트 ID}
먼저 프로젝트 리스트를 확인해서 나온 프로젝트 ID를 가지고 set 명령어를 사용해 설정을 완료해줍니다.
그럼 인증설정이 완료됩니다!
3. 구현
아래 문서에 자바 예시코드가 있으므로 하나씩 따라해보겠습니다.
REST, RPC 방법 2가지로 구현이 가능한데 저는 라이브러리를 이용한 RPC 방법으로 구현했고, v2 버전을 사용했습니다!

https://docs.cloud.google.com/speech-to-text/docs/libraries?hl=ko#client-libraries-install-java
Cloud Speech-to-Text 클라이언트 라이브러리 | Google Cloud Documentation
의견 보내기 Cloud Speech-to-Text 클라이언트 라이브러리 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 이 페이지에서는 Cloud Speech-to-Text API의 Cloud 클라이언트
docs.cloud.google.com
implementation 'com.google.cloud:google-cloud-speech:4.75.0'
먼저 라이브러리 의존성을 주입해줍니다.
google:
cloud:
project-id: {my project-id}
location: {my location}
recognizer-name: {my recognizer}
그리고 아까 만든 프로젝트 관련 설정을 application.yml에 추가한다

🔥 🔥🔥 참고로 여기 project-id는 위에서 보이는 빨강 마스킹된 ID를 넣는게 아닙니다!
ID를 한번더 클릭하면 아래 페이지로 넘어가는데

바로 여기서 위에 인식기에 나오는 projects/ 뒤에 노란 마스킹된 숫자를 넣어야합니다!
@Configuration
public class SpeechConfig {
@Bean(destroyMethod = "close")
SpeechClient speechClient() throws Exception {
return SpeechClient.create();
}
}@Slf4j
@RequiredArgsConstructor
@RequestMapping("/api/order")
@RestController
public class OrderController {
private final OrderService orderService;
@PostMapping(value = "/speech/transcribe", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public ResultResponse<TranscribeSpeechResponse> transcribeSpeech(@RequestPart("audio") MultipartFile audio) {
if (audio.isEmpty()) {
throw new AudioFileEmptyException();
}
final byte[] audioBytes;
try {
audioBytes = audio.getBytes();
} catch (IOException e) {
throw new AudioFileReadFailedException();
}
return new ResultResponse<>(orderService.transcribeSpeech(audioBytes));
}
}@Slf4j
@RequiredArgsConstructor
@Service
public class OrderService {
@Value("${google.cloud.project-id}")
private String projectId;
@Value("${google.cloud.location}")
private String location;
@Value("${google.cloud.recognizer-name}")
private String recognizerName;
private final SpeechClient speechClient;
private String recognizerResourceName;
@PostConstruct
void init() {
recognizerResourceName =
String.format("projects/%s/locations/%s/recognizers/%s", projectId, location, recognizerName);
}
public TranscribeSpeechResponse transcribeSpeech(byte[] audioBytes) {
try {
RecognitionConfig config = RecognitionConfig.newBuilder()
.setAutoDecodingConfig(AutoDetectDecodingConfig.newBuilder().build())
.build();
RecognizeRequest request = RecognizeRequest.newBuilder()
.setConfig(config)
.setRecognizer(recognizerResourceName)
.setContent(ByteString.copyFrom(audioBytes))
.build();
RecognizeResponse response = speechClient.recognize(request); // 변환 발송
String text = response.getResultsList().stream()
.map(r -> r.getAlternativesCount() > 0 ? r.getAlternatives(0).getTranscript() : "")
.filter(s -> !s.isBlank())
.collect(Collectors.joining("\n"));
return new TranscribeSpeechResponse(text);
} catch (Exception e) {
log.error("STT failed", e);
throw new SpeechToTextFailedException();
}
}
}
그리고 config와 컨트롤러 서비스를 코드를 작성하면 완성입니다.
{
"text": "여기 생수 두 병 주문이요"
}
결과는 이렇게 나온다. 음성인식이 꽤나 잘되는 편이라 깜짝놀랐다 ㅋㅋㅋㅋㅋㅋ
io.grpc.StatusRuntimeException: INVALID_ARGUMENT:
RecognitionAudio empty. Either content or uri must be specified.
여담으로,
코드를 만들고 테스트를 하는데 계속 이 오류가 나서 상당히 애를 먹었었다 😵💫
content가 잘들어갔는데 자꾸 비어있다고 나오는,,
문제의 원인은 M4A 음성파일을 사용해서였다.
M4A는 컨테이너 형식이며 내부에 AAC 코덱을 사용하는데 AutoDetectDecodingConfig가 이를 제대로 감지하지 못해서 그런것이였다.
같은 파일을 MAW 형식으로 변환해서 테스트하니 바로 통과가 됐다!
'백엔드' 카테고리의 다른 글
| Redis 사용하여 JWT RefreshToken 저장하기 (0) | 2025.04.03 |
|---|---|
| UPSERT의 동작원리와 기준 컬럼 설정 유의점 (0) | 2025.03.14 |
| DB의 날짜와 프론트의 날짜 다른(1일 더 차이나는) 오류 해결 (0) | 2025.03.14 |
| application-dev.yml 적용하는 방법 (0) | 2025.02.20 |
| CORS 오류 해결 방법 - Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. (0) | 2025.02.14 |